
Inhaltsverzeichnis
Die Datenanalyse ist der Arbeitsschritt, in dem aus deinen erhobenen Rohdaten verwertbare Erkenntnisse werden. Du bereinigst die Daten, wählst passende Analysemethoden, wertest systematisch aus und stellst die Ergebnisse in Tabellen und Diagrammen dar. Der konkrete Ablauf hängt davon ab, ob du quantitativ mit Zahlen oder qualitativ mit Texten arbeitest. Die Vorgaben variieren je nach Fachbereich und Lehrstuhl, deshalb solltest du frühzeitig mit deiner Betreuung klären, welche Verfahren und welche Software erwartet werden.
Lege Auswertungsverfahren und Ausschlussregeln möglichst vor dem Blick auf die Ergebnisse fest. So trennst du begründete Analyseentscheidungen von nachträglicher Ergebnisoptimierung und schaffst eine saubere Grundlage für den Ergebnisteil.
Datenanalyse in vier Schritten: 1. Daten bereinigen (Ausreißer, fehlende Werte dokumentieren), 2. Analysemethode passend zur Forschungsfrage wählen, 3. Auswertung durchführen und Voraussetzungen prüfen, 4. Ergebnisse mit Tabellen, Diagrammen und Fließtext darstellen.
Was ist Datenanalyse in der Bachelorarbeit?
In der Datenanalyse wertest du das Material aus, das du durch Umfragen, Interviews, Experimente oder andere Erhebungsmethoden gesammelt hast. Das Ziel ist, Muster zu erkennen, Zusammenhänge zu prüfen und deine Forschungsfrage zu beantworten. Anders als beim bloßen Zusammenfassen geht es darum, deine Hypothesen systematisch zu testen oder aus dem Material neue Erkenntnisse zu gewinnen.
Der Ablauf hängt davon ab, ob du quantitativ oder qualitativ arbeitest. Bei quantitativen Studien rechnest du mit Zahlen und statistischen Verfahren: Du testest, ob Unterschiede zwischen Gruppen signifikant sind oder ob Variablen zusammenhängen. Bei qualitativen Studien analysierst du Texte, Aussagen oder Beobachtungen auf inhaltliche Muster: Du kodierst Passagen, bildest Kategorien und arbeitest zentrale Themen heraus. Manche Arbeiten kombinieren beide Ansätze im Mixed-Methods-Design.
Die Datenanalyse bildet das Herzstück deines empirischen Teils. Ohne saubere Auswertung bleiben deine Daten nur Rohmaterial. Erst durch die Analyse entstehen Erkenntnisse, die du in der Diskussion interpretieren und in den Forschungsstand einordnen kannst.
Zeitplanung: Wie lange dauert die Datenanalyse?
Die Dauer der Datenanalyse variiert stark je nach Methode, Datenumfang und deiner Vorerfahrung mit der Software. Eine pauschale Angabe wie „2 bis 4 Wochen" ist wenig hilfreich, weil sie die Unterschiede zwischen Projekten ignoriert. Orientiere dich stattdessen an diesen Richtwerten für typische Szenarien in Bachelorarbeiten.
Eine quantitative Studie mit Online-Umfrage und etwa 100 bis 200 Teilnehmenden benötigt typischerweise 1 bis 2 Wochen für Datenbereinigung und deskriptive Statistik. Wenn du zusätzlich Hypothesentests wie t-Tests oder Korrelationen durchführst, rechne mit einer weiteren Woche. Komplexere Verfahren wie Regressionsanalysen mit mehreren Prädiktoren oder Varianzanalysen mit Interaktionseffekten können 2 bis 3 Wochen dauern, besonders wenn du noch Voraussetzungen prüfen und gegebenenfalls alternative Verfahren wählen musst.
Eine qualitative Studie mit Interviews hat einen anderen Rhythmus. Die Transkription allein dauert pro Interviewstunde etwa 4 bis 6 Stunden. Bei 10 Interviews à 45 Minuten sind das bereits 30 bis 45 Stunden reine Transkriptionsarbeit. Das anschließende Kodieren und Kategorisieren benötigt erfahrungsgemäß noch einmal ähnlich viel Zeit. Plane für eine qualitative Analyse mit 8 bis 12 Interviews insgesamt 4 bis 6 Wochen ein.
Plane idealerweise mindestens eine Woche Puffer ein. Bei komplexen Analysen mit mehreren Verfahren oder bei wenig Vorerfahrung mit der Software können auch zwei Wochen sinnvoll sein. Bei einfachen deskriptiven Auswertungen mit vertrauten Tools reichen oft wenige Tage. Unerwartete Probleme wie fehlende Daten oder verletzte Voraussetzungen treten häufig auf. Besprich deinen Zeitplan frühzeitig mit deiner Betreuung.
Vorbereitung: Daten bereinigen und strukturieren
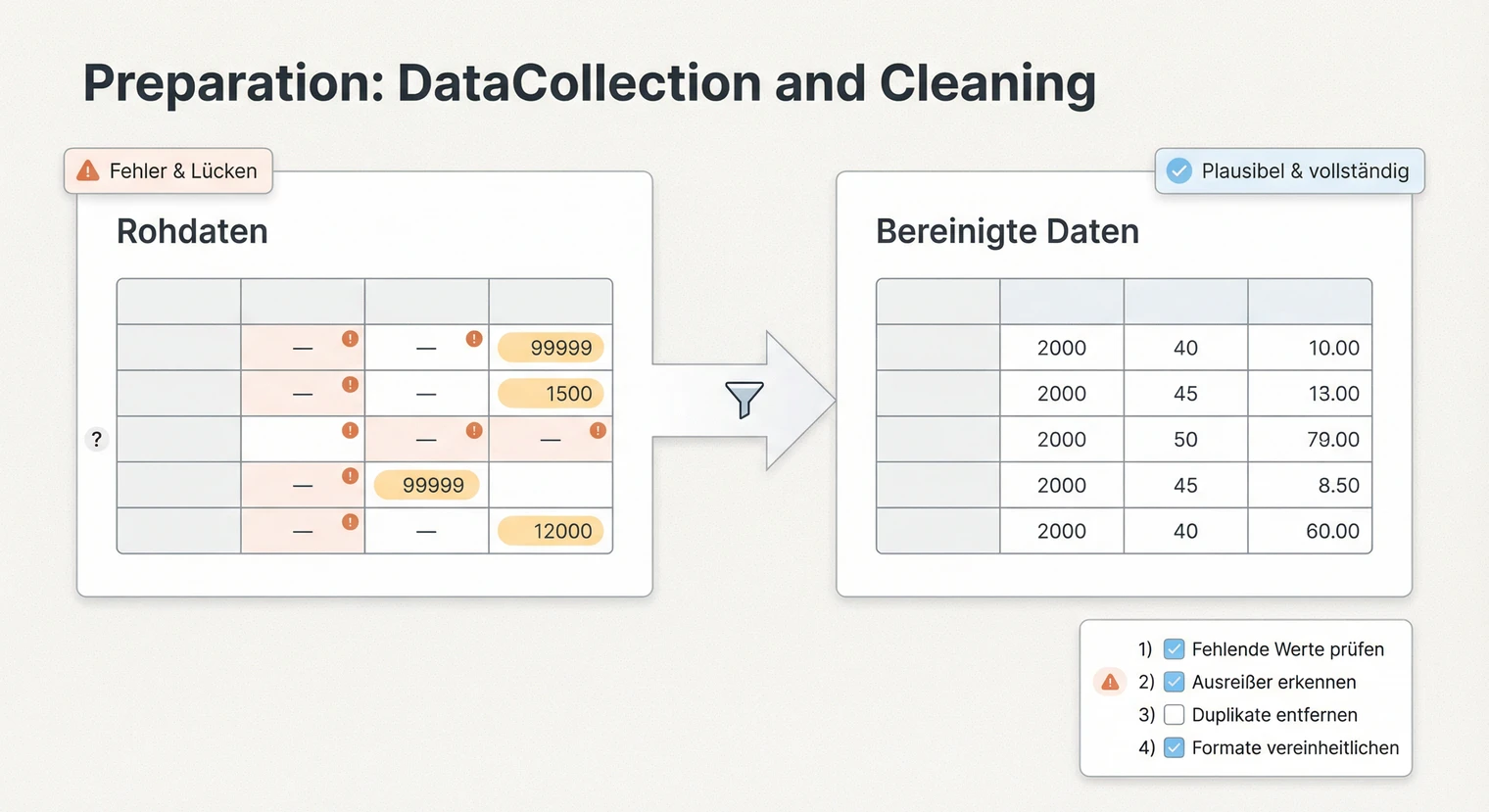
Bevor du mit der eigentlichen Analyse beginnst, müssen deine Daten vollständig und sauber vorliegen. Dieser Schritt wird oft unterschätzt, ist aber entscheidend für die Qualität deiner Ergebnisse. Fehler in der Datenbereinigung pflanzen sich durch alle weiteren Analysen fort.
Bei quantitativen Daten prüfst du zunächst die Vollständigkeit. Fehlen Antworten bei einzelnen Fragen? Gibt es unplausible Werte, etwa ein Alter von 200 Jahren oder negative Werte bei einer Skala, die nur positive Werte erlaubt? Solche Fälle dokumentierst du in einer Bereinigungstabelle: Wie viele Datensätze sind betroffen? Was ist das Problem? Wie hast du entschieden?
Fehlende Werte erfordern eine bewusste Entscheidung. Das einfache Ersetzen durch den Mittelwert ist nur in bestimmten Fällen sinnvoll, etwa wenn wenige Werte zufällig fehlen. Wenn systematisch Werte fehlen (etwa weil bestimmte Personen eine Frage nicht beantworten wollten), kann der Mittelwert-Ersatz die Ergebnisse verfälschen. Alternativen sind das Ausschließen unvollständiger Datensätze (Listwise Deletion, reduziert aber die Stichprobe), das paarweise Ausschließen (Pairwise Deletion, nutzt alle verfügbaren Daten pro Analyse, kann aber zu unterschiedlichen Stichproben je Auswertung führen und die Vergleichbarkeit erschweren) oder fortgeschrittene Verfahren wie Multiple Imputation. Dokumentiere deine Strategie und begründe sie im Methodenteil.
Bei qualitativen Daten steht die Transkription am Anfang. Lege vorher Transkriptionsregeln fest: Notierst du Pausen, Betonungen, Füllwörter? Je nach Forschungsfrage reicht oft eine einfache wörtliche Transkription. Kennzeichne jedes Interview eindeutig (I1, I2, ...) und nummeriere die Absätze, damit du später Zitate präzise zuordnen kannst.
Organisiere deine Dateien so, dass du jeden Schritt nachvollziehen kannst. Bewährt hat sich eine Ordnerstruktur mit: Rohdaten (unverändert), bereinigte Daten (nach Bereinigung), Syntax-Dateien (SPSS, R) oder Kodier-Dateien (MAXQDA), Outputs (Tabellen, Diagramme). So kannst du bei Rückfragen der Betreuung jeden Schritt belegen.
Quantitative Datenanalyse: Vorgehen und Verfahren

Die quantitative Analyse arbeitet mit Zahlen und statistischen Verfahren. Du beschreibst deine Stichprobe, testest Hypothesen und quantifizierst Effekte. Der zentrale Schritt ist die Wahl des richtigen Verfahrens, denn nicht jeder Test passt zu jeder Fragestellung.
Schritt 1: Deskriptive Statistik
Beginne immer mit einer Beschreibung deiner Stichprobe. Wie viele Personen haben teilgenommen? Wie verteilen sich Alter, Geschlecht oder andere relevante Merkmale? Berechne für deine zentralen Variablen Mittelwerte (M), Standardabweichungen (SD), Minimum und Maximum. Dieser Überblick zeigt, mit welchen Daten du arbeitest und ob die Stichprobe zur Zielgruppe passt.
Schritt 2: Das richtige Verfahren wählen
Die Wahl des statistischen Verfahrens hängt von zwei Fragen ab: Was willst du herausfinden (Unterschied, Zusammenhang, Vorhersage)? Und welches Skalenniveau haben deine Variablen (metrisch, ordinal, nominal)? Für einen Gruppenvergleich zwischen zwei unabhängigen Gruppen mit metrischer abhängiger Variable nutzt du einen t-Test für unabhängige Stichproben. Vergleichst du dieselben Personen zu zwei Zeitpunkten, ist es ein t-Test für abhängige Stichproben. Bei mehr als zwei Gruppen rechnest du eine Varianzanalyse (ANOVA).
Für Zusammenhänge zwischen zwei metrischen Variablen nutzt du eine Pearson-Korrelation. Ist mindestens eine Variable ordinal, wählst du die Spearman-Korrelation. Willst du Vorhersagen treffen (etwa: Welche Faktoren beeinflussen die Arbeitszufriedenheit?), rechnest du eine Regressionsanalyse. Bei einer nominalen abhängigen Variable (ja/nein) ist es eine logistische Regression.
- Unterschied zwischen 2 Gruppen? → t-Test (unabhängig oder gepaart)
- Unterschied zwischen 3+ Gruppen? → ANOVA
- Zusammenhang zwischen 2 Variablen? → Korrelation (Pearson oder Spearman)
- Einfluss mehrerer Faktoren vorhersagen? → Regression
- Ja/Nein-Ergebnis vorhersagen? → Logistische Regression
Schritt 3: Voraussetzungen prüfen
Jedes statistische Verfahren hat Voraussetzungen, die du vor der Analyse prüfen musst. Die häufigsten sind Normalverteilung, Varianzhomogenität bei Gruppenvergleichen (Levene-Test) und Unabhängigkeit der Beobachtungen (durch dein Studiendesign sichergestellt). Wichtig: Je nach Verfahren gelten unterschiedliche Annahmen. Bei t-Tests und ANOVAs prüfst du die Normalverteilung der abhängigen Variable innerhalb der Gruppen. Bei Regressionen bezieht sich die Normalverteilungsannahme auf die Residuen, nicht auf die Variablen selbst. Zusätzlich prüfst du bei Regressionen: Linearität (ist der Zusammenhang linear?), Homoskedastizität (sind die Residuen gleichmäßig verteilt?) und Multikollinearität (korrelieren die Prädiktoren zu stark untereinander?). Als grobe Orientierung gelten VIF-Werte über 10 als kritisch, manche Fachbereiche nutzen aber strengere Schwellen (z.B. VIF > 5). Prüfe auch Ausreißer und einflussreiche Fälle (z.B. über Cook's Distance).
Bei der Normalverteilungsprüfung ist wichtig: Tests wie Shapiro-Wilk werden bei größeren Stichproben (ab ca. 50 Fällen) sehr schnell signifikant, auch bei geringen Abweichungen. Visuelle Prüfungen mit Histogramm oder Q-Q-Plot sind daher oft hilfreicher als reine Testwerte. Wenn Voraussetzungen verletzt sind, hast du Optionen: Du nutzt ein robustes Verfahren (etwa Welch-t-Test statt klassischem t-Test), ein nicht-parametrisches Verfahren (Mann-Whitney-U statt t-Test) oder transformierst deine Daten. Dokumentiere im Methodenteil, welche Voraussetzungen du geprüft hast und wie du mit Verletzungen umgegangen bist.
t-Test: „Die Experimentalgruppe (M = 4.2, SD = 0.8) unterschied sich signifikant von der Kontrollgruppe (M = 3.5, SD = 0.9), t(98) = 4.12, p < .001, d = 0.82."
Korrelation: „Es zeigte sich ein signifikanter positiver Zusammenhang zwischen Arbeitszufriedenheit und Commitment, r = .45, p < .01, 95%-KI [.28, .59]."
Regression: „Das Modell erklärte 34% der Varianz in der Arbeitszufriedenheit, F(3, 96) = 16.4, p < .001, R² = .34. Autonomie war der stärkste Prädiktor, β = .42, p < .001."
Hinweis: Diese Beispiele sind Muster, die du an dein Design anpassen musst (z.B. gepaarter vs. ungepaarter t-Test). Die passende Effektstärke variiert je nach Verfahren (d bei t-Tests, η² bei ANOVA, Odds Ratio bei logistischer Regression). Passe auch die Formatierung an die Vorgaben deines Fachbereichs an.
Software für quantitative Analysen: SPSS ist an vielen Hochschulen Standard und bietet eine grafische Oberfläche. R ist kostenlos und flexibler, erfordert aber Einarbeitung in die Programmiersprache. Für einfache Auswertungen wie deskriptive Statistiken und t-Tests reicht oft Excel. Frag deine Betreuung, welche Tools empfohlen werden und ob dein Fachbereich Lizenzen bereitstellt.
Qualitative Datenanalyse: Kodieren und Kategorisieren
Die qualitative Analyse arbeitet mit Texten, Interviews oder Beobachtungen. Du suchst nach Mustern, Themen und Bedeutungen. Das Vorgehen ist systematischer als oft angenommen und folgt klaren Schritten.
Vorgehen bei der qualitativen Inhaltsanalyse
Die qualitative Inhaltsanalyse nach Mayring ist eine der verbreitetsten Methoden. Du arbeitest dich dabei in mehreren Durchgängen durch dein Material. Im ersten Durchgang liest du alle Transkripte und markierst relevante Passagen. Im zweiten Durchgang vergibst du Codes, also kurze Bezeichnungen für den Inhalt einer Passage. Im dritten Durchgang gruppierst du ähnliche Codes zu Kategorien. Im vierten Durchgang prüfst du das Kategoriensystem am gesamten Material und überarbeitest es bei Bedarf. Im fünften Durchgang analysierst du die Kategorien: Wie häufig treten sie auf? Welche Zusammenhänge gibt es? Was sind typische Aussagen?
Interviewaussage (I3, Abs. 24): „Am Anfang war ich total überfordert mit der ganzen Technik. Aber nach zwei Wochen ging das dann."
Code: „Anfängliche technische Überforderung" + „Gewöhnungseffekt"
Kategorie: „Einarbeitungsphase" (zusammen mit ähnlichen Codes wie „Lernkurve", „Anfangsschwierigkeiten")
Ergebnis-Satz: „Die Kategorie ‚Einarbeitungsphase' trat bei 8 von 10 Befragten auf. Typisch war eine anfängliche Überforderung, die nach etwa zwei Wochen einem routinierteren Umgang wich."
Deduktiv oder induktiv? Bei der deduktiven Vorgehensweise leitest du Kategorien vorab aus der Theorie ab und prüfst, ob sie im Material vorkommen. Bei der induktiven Vorgehensweise entwickelst du Kategorien direkt aus dem Material. In der Praxis kombinieren die meisten Arbeiten beide Ansätze: Du startest mit theoriegeleiteten Kategorien und ergänzt induktiv, was du zusätzlich findest.
Qualitätssicherung beim Kodieren: Um dein Kategoriensystem abzusichern, empfiehlt sich eine Pilot-Kodierung: Kodiere zunächst zwei bis drei Interviews und überarbeite das Codebuch, bevor du das gesamte Material bearbeitest. Das Codebuch dokumentiert jede Kategorie mit Definition, Ankerbeispiel und Abgrenzungsregeln. Falls möglich, lass eine zweite Person einen Teil des Materials kodieren und vergleiche die Zuordnungen (Intercoder-Reliabilität). Im Ergebnisteil belegst du deine Kategorien mit prägnanten Originalzitaten und gibst die Quelle an (z.B. I3, Abs. 24). Achte dabei auf Datenschutz: Je nach Einwilligung der Teilnehmenden musst du Zitate anonymisieren (Namen, Orte, identifizierende Details ersetzen) oder kürzen. So können Lesende nachvollziehen, wie du von den Daten zu den Kategorien gekommen bist, ohne dass die Anonymität der Befragten gefährdet wird.
Software für qualitative Analysen: MAXQDA und ATLAS.ti sind spezialisierte Programme, die das Kodieren, Sortieren und Visualisieren erleichtern. Sie bieten Funktionen wie automatische Häufigkeitszählungen, Code-Kookkurrenz-Analysen und Export-Optionen für Tabellen. Für kleinere Projekte mit wenigen Interviews funktioniert auch eine strukturierte Tabelle in Word oder Excel, in der du Textstellen, Codes und Kategorien zuordnest.
Führe ein Forschungstagebuch während der Analyse. Notiere Entscheidungen (warum hast du zwei Codes zusammengelegt?), Zweifel (passt diese Aussage wirklich in die Kategorie?) und Einsichten (was fällt auf?). Das hilft dir, dein Vorgehen im Methodenteil nachvollziehbar zu beschreiben und zeigt methodische Reflexion.
Ergebnisse darstellen: Tabellen, Diagramme, Text

Die Darstellung deiner Ergebnisse entscheidet darüber, ob Lesende deine Analyse nachvollziehen können. Die Grundregel lautet: Im Text beschreibst du die wichtigsten Befunde in Worten, in Tabellen zeigst du präzise Zahlen, in Diagrammen visualisierst du Muster und Verteilungen.
Tabellen richtig aufbauen
Tabellen eignen sich für präzise Zahlen, die Lesende nachschlagen wollen. Eine typische deskriptive Tabelle hat die Spalten Variable, n, M (Mittelwert), SD (Standardabweichung). Eine Inferenzstatistik-Tabelle enthält zusätzlich Testkennwerte, df, p und Effektstärke. Nummeriere jede Tabelle (Tabelle 1, Tabelle 2, ...) und gib ihr einen aussagekräftigen Titel über der Tabelle. Der Titel sollte so präzise sein, dass die Tabelle auch ohne den umgebenden Text verständlich ist.
Was gehört in den Text, was in die Tabelle?
Im Fließtext beschreibst du die zentralen Befunde und ihre Bedeutung für deine Forschungsfrage. Du nennst die wichtigsten Zahlen (etwa den Mittelwertsunterschied und den p-Wert), aber du wiederholst nicht alle Werte aus der Tabelle. Ein gutes Vorgehen: Beschreibe das Ergebnis in einem Satz, verweise auf die Tabelle für Details. Beispiel: „Die Experimentalgruppe zeigte signifikant höhere Werte als die Kontrollgruppe (siehe Tabelle 3 für deskriptive Statistiken und Testergebnisse)."
Diagramme gezielt einsetzen
Diagramme machen Verteilungen und Trends sichtbar. Balkendiagramme eignen sich für Häufigkeiten und Gruppenvergleiche, Liniendiagramme für Verläufe über Zeit, Streudiagramme für Zusammenhänge zwischen Variablen. Achte auf beschriftete Achsen (mit Einheit), eine Legende und einen Titel unter der Abbildung. Verzichte auf 3D-Effekte, Schattierungen und unnötige Farben, sie erschweren das Ablesen.
Dein Zitierstil gibt oft vor, wie Tabellen und Abbildungen formatiert werden. APA verlangt etwa nur horizontale Linien (keine vertikalen), Titel über Tabellen und unter Abbildungen. Prüfe die Vorgaben deiner Hochschule oder deines Fachbereichs, bevor du formatierst.
Typische Fehler und wie du sie vermeidest

- Falsches Verfahren wählen: Ein t-Test für abhängige Stichproben bei unabhängigen
Gruppen liefert falsche Ergebnisse.
Gegenmaßnahme: Frag dich vor jeder Analyse: Was ist meine Fragestellung (Unterschied, Zusammenhang, Vorhersage)? Wie viele Gruppen/Variablen habe ich? Welches Skalenniveau haben meine Daten? Nutze eine Entscheidungshilfe wie die Verfahrensübersicht weiter oben oder frag deine Betreuung. - Datenbereinigung unterschätzen: Fehlende oder fehlerhafte Daten verfälschen jede
Analyse, und das Ersetzen durch Mittelwerte kann die Ergebnisse verzerren.
Gegenmaßnahme: Dokumentiere jeden Bereinigungsschritt in einer separaten Tabelle. Begründe deine Strategie für fehlende Werte (Ausschluss, Imputation, ...) im Methodenteil. Führe bei kritischen Entscheidungen eine Sensitivitätsanalyse durch: Ändert sich das Ergebnis, wenn du anders bereinigst? - Signifikanz überinterpretieren: Ein p-Wert unter .05 sagt nur, dass ein Effekt
statistisch von Null verschieden ist, nicht dass er groß oder praktisch relevant ist.
Gegenmaßnahme: Berichte immer auch die Effektstärke (Cohen's d, r, η²). Die oft zitierten Schwellen (d = 0.2 klein, d = 0.5 mittel, d = 0.8 groß) sind grobe Konventionen, keine festen Regeln. Die praktische Bedeutung hängt vom Kontext ab: In der Medizin kann ein kleiner Effekt lebensrettend sein, in anderen Bereichen irrelevant. Ordne die Effektstärke inhaltlich ein und berichte auch bei nicht signifikanten Ergebnissen Effektstärke und Konfidenzintervall. - Ergebnisse und Interpretation vermischen: Im Ergebnisteil gehört nur, was du gefunden
hast, nicht was es bedeutet.
Gegenmaßnahme: Trenne konsequent: Im Ergebnisteil beschreibst du Zahlen und Befunde (Die Gruppen unterschieden sich signifikant, ...). In der Diskussion interpretierst du (Dieser Unterschied könnte darauf hindeuten, dass ...). Wenn du dich beim Schreiben fragst „Warum ist das so?", gehört es in die Diskussion. - Negative Ergebnisse verschweigen: Wenn eine Hypothese nicht bestätigt wurde, ist
das ein Ergebnis.
Gegenmaßnahme: Dokumentiere auch nicht signifikante Befunde ehrlich. Diskutiere mögliche Gründe (zu kleine Stichprobe? Messinstrument ungeeignet? Effekt existiert nicht?). Transparenz ist ein Qualitätsmerkmal wissenschaftlicher Arbeit.
Nächster Schritt: Von der Analyse zur Diskussion
Deine Datenanalyse ist abgeschlossen, wenn du alle relevanten Auswertungen durchgeführt und die Ergebnisse nachvollziehbar dargestellt hast. Prüfe: Beantwortet die Analyse deine Forschungsfrage? Sind alle Tabellen und Diagramme korrekt beschriftet? Ist das Vorgehen im Methodenteil dokumentiert? Sind Bereinigungsschritte und Entscheidungen nachvollziehbar?
Im nächsten Schritt interpretierst du deine Befunde in der Diskussion. Dort ordnest du die Ergebnisse in den Forschungsstand ein, diskutierst Limitationen und ziehst Schlussfolgerungen. Die Datenanalyse liefert die Fakten, die Diskussion gibt ihnen Bedeutung.
Sichere deine Daten und Analysedateien sorgfältig. Manche Hochschulen verlangen, dass du Rohdaten, Syntax-Dateien und Outputs im Anhang oder auf einem Datenträger einreichst. Kläre das rechtzeitig mit deiner Betreuung.
Wenn deine Arbeit fertig ist, steht der letzte Schritt an: Drucken und Binden. Achte darauf, dass du genügend Zeit für eventuelle Korrekturen einplanst und prüfe die Druckvorschau sorgfältig. Bei empirischen Arbeiten mit umfangreichem Anhang lohnt sich eine stabile Bindung, die auch bei häufigem Blättern hält.
Häufig gestellte Fragen
Wann beginne ich mit der Datenanalyse in meiner Bachelorarbeit?
Lege vorab fest, wann dein Datensatz geschlossen wird und welche Qualitätsprüfungen vor der eigentlichen Analyse nötig sind. Viele Arbeitsschritte kannst du mit Testdaten vorbereiten. Schätze Bereinigung, Transkription und Kodierung anhand einer repräsentativen Teilmenge, statt die Dauer aus einer fremden Fallzahl abzuleiten.
Welche Software eignet sich für die Datenanalyse?
Das hängt von deinem Forschungsansatz ab. Für quantitative Analysen sind SPSS, R oder Excel verbreitet. Für qualitative Auswertungen nutzen viele MAXQDA oder ATLAS.ti. Frag deine Betreuung, welche Tools an deiner Hochschule üblich sind und ob Lizenzen zur Verfügung stehen.
Wie gehe ich mit Ausreißern in meinen Daten um?
Prüfe zunächst, ob der Ausreißer ein Eingabefehler ist (dann korrigieren) oder ein echter, aber extremer Wert. Bei echten Ausreißern hast du mehrere Optionen: Wert beibehalten und robuste Verfahren nutzen, Wert ausschließen mit Begründung, oder Wert winsorisieren (auf einen Grenzwert setzen). Dokumentiere deine Entscheidung immer im Methodenteil.
Was mache ich, wenn meine Ergebnisse nicht signifikant sind?
Nicht signifikante Ergebnisse sind keine schlechten Ergebnisse. Berichte Schätzwert, Konfidenzintervall, Test und Voraussetzungen. Diskutiere, welche Effektgrößen mit den Daten noch vereinbar sind und ob Präzision, Messung oder Design die Aussage begrenzen. Ein nicht signifikanter Test beweist weder einen Nulleffekt noch automatisch zu wenig Power.
Was gehört in den Ergebnisteil und was in den Anhang?
In den Ergebnisteil gehören die zentralen Befunde sowie die Tabellen und Abbildungen, die Leser für die Aussage brauchen. Ergänzende Outputs oder Instrumente können nach Leitfaden in den Anhang. Rohdaten und Transkripte gehören nur hinein, wenn Prüfungs-, Datenschutz-, Einwilligungs- und Übermittlungsvorgaben das zulassen; pseudonymisierte Daten können weiterhin personenbezogen sein.
Wie viele Daten brauche ich für eine aussagekräftige Analyse?
Die benötigte Stichprobengröße hängt von Forschungsziel, relevanter Effektgröße oder Zielpräzision, Alpha, gewünschter Power und Design ab. Faustregeln wie „30 pro Gruppe" oder „10 Fälle pro Prädiktor" können zu klein oder unnötig groß sein. Qualitative Fallzahlen leitest du aus Ansatz, Sampling, Heterogenität, Informationsdichte und Auswertung ab; theoretische Sättigung passt nicht zu jedem qualitativen Design.
 Wissenschaftliche Kommunikation
Wissenschaftliche Kommunikation  Die richtige Zitierweise
Die richtige Zitierweise  Einleitung der Bachelorarbeit
Einleitung der Bachelorarbeit