Inhaltsverzeichnis
Die Datenanalyse deiner Masterarbeit verwandelt erhobene Daten in verwertbare Erkenntnisse. Sie ist der Kern deiner empirischen Arbeit und entscheidet darüber, ob du deine Forschungsfrage beantworten kannst. Hier erfährst du, wie du systematisch vorgehst, welche Software sich eignet und welche Methoden zu deinen Daten passen. (Dieser Artikel richtet sich an empirische Masterarbeiten mit quantitativer oder qualitativer Auswertung, ob eigene Erhebung oder Sekundärdaten wie Panel-, Register- oder Open Data. Bei rein theoretischen Arbeiten entfällt die statistische Datenanalyse; dort kann aber eine systematische Literatur- oder Dokumentenanalyse relevant sein.)
Kurzantwort: Eine gute Datenanalyse beginnt mit sauberer Datenaufbereitung. Wähle dann das passende Verfahren für deine Forschungsfrage und dein Datenniveau. Dokumentiere jeden Schritt transparent, damit deine Ergebnisse nachvollziehbar sind. Plane dafür vorab ein nachvollziehbares Datenmanagement und protokolliere, wie du fehlende Werte und Bereinigungsschritte behandelst. Wenn du nur 10 Minuten hast: Schnellcheck unten → Voraussetzungen prüfen → Methode aus Matrix wählen → Reporting-Checkliste nutzen.
Datentyp? Nominal/kategorial → χ²/Fisher, Cramér's V. Ordinal → Rangkorrelation (Spearman), Rangtests (Mann-Whitney, Kruskal-Wallis), ggf. ordinale Regression. Metrisch → parametrisch möglich (Pearson, t-Test, ANOVA, Regression).
Ziel? Zusammenhang prüfen → Korrelation/Regression. Gruppenvergleich → t-Test/ANOVA. Vorhersage → Regression.
Design? Unabhängige Gruppen → t-Test unabhängig. Messwiederholung → t-Test abhängig, ANOVA mit Messwiederholung (+ Sphärizität prüfen).
Voraussetzungen erfüllt? Ja → parametrisch. Nein → nicht-parametrische Alternative oder robuste Variante.
Vorgaben können je nach Fach und Lehrstuhl variieren. Im Zweifel: Betreuung fragen und Entscheidung im Methodenteil begründen.
Die Angaben in diesem Artikel sind Orientierungswerte. Welche Analyseverfahren und Software erwartet werden, kann je nach Studiengang und Lehrstuhl variieren. Prüfe die Richtlinien deines Fachbereichs und sprich mit deiner Betreuung.
Der Analyseprozess im Überblick
Bevor du mit der eigentlichen Analyse startest, hilft ein klarer Prozess. Die meisten Datenanalysen folgen einem ähnlichen Ablauf, unabhängig davon, ob du quantitativ oder qualitativ arbeitest.
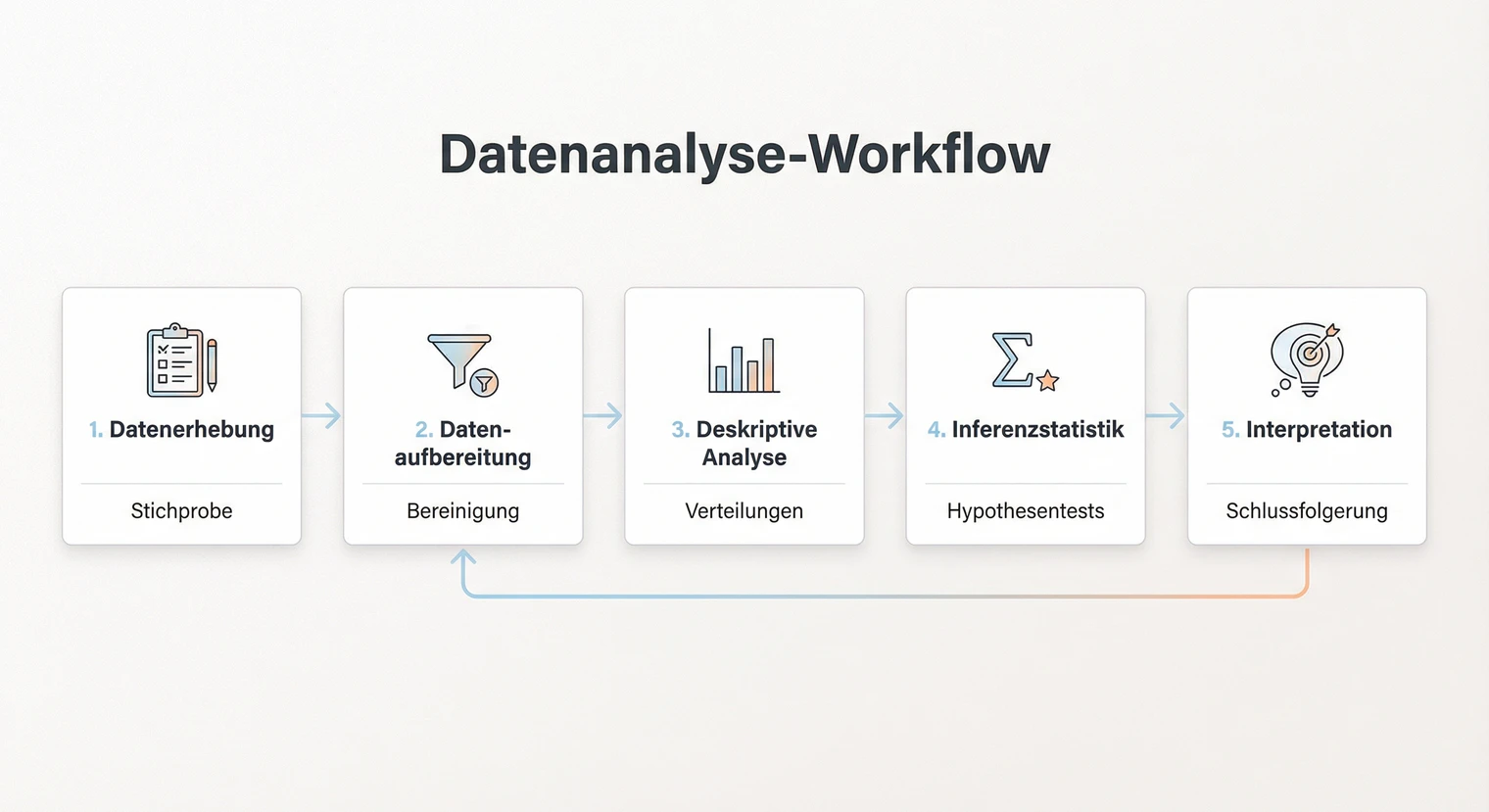
Der Prozess beginnt mit der Datenaufbereitung. Hier prüfst du deine Rohdaten auf Fehler, bereinigst sie und bringst sie in ein analysierbares Format. Dieser Schritt nimmt oft mehr Zeit in Anspruch als die eigentliche Auswertung, ist aber entscheidend für die Qualität deiner Ergebnisse.
Danach folgt die deskriptive Analyse. Du beschreibst deine Daten mit Kennzahlen wie Mittelwert, Standardabweichung oder Häufigkeiten. So bekommst du einen ersten Überblick und erkennst Auffälligkeiten. Erst dann startest du mit der inferenzstatistischen Auswertung, bei der du Hypothesen testest und Zusammenhänge prüfst.
Der letzte Schritt ist die Interpretation. Wichtig: Im Ergebnisteil deiner Arbeit berichtest du nur, was du gefunden hast. Die eigentliche Interpretation, also das Einordnen in den Forschungskontext und das Ableiten von Schlussfolgerungen, gehört in die Diskussion. Diese Trennung hilft dir, sachlich zu bleiben und Überinterpretation zu vermeiden.
Datenaufbereitung: Der erste Schritt
Saubere Daten sind die Grundlage jeder Analyse. Die Datenaufbereitung ist kein glamouröser, aber ein unverzichtbarer Schritt. Fehler, die hier entstehen, ziehen sich durch die gesamte Auswertung.
Prüfe deine Daten auf Eingabefehler, unplausible Werte und Ausreißer. Ein Alter von 999 oder eine negative Zeitangabe sind offensichtliche Fehler. Ausreißer identifizieren: Boxplots zeigen Werte außerhalb der Whisker (1,5-facher Interquartilsabstand). Für spezifische Verfahren wie Regression gibt es zusätzliche Diagnostiken (siehe Abschnitt „Voraussetzungen prüfen").
Umgang mit Ausreißern: Nicht automatisch löschen. Prüfe: Eingabefehler? Dann korrigieren oder auf fehlend setzen. Echter Extremfall? Dann: (1) Analyse mit und ohne Ausreißer durchführen, (2) Ergebnisse vergleichen, (3) beide berichten oder Entscheidung begründen.
Wichtig: Erstelle eine Kopie deiner Rohdaten, bevor du Änderungen vornimmst.
Fehlende Werte (Missings) kommen in fast jedem Datensatz vor. Schritt 1: Dokumentiere Anteil und Muster. Fehlen Daten zufällig oder systematisch? Es gibt drei Muster: MCAR (Missing Completely At Random, komplett zufällig), MAR (Missing At Random, zufällig bedingt auf andere Variablen) und MNAR (Missing Not At Random, systematisch). Bei MCAR/MAR sind die meisten Verfahren anwendbar, bei MNAR drohen Verzerrungen.
Strategien: Listwise deletion (Fallausschluss) bei wenigen zufälligen Missings (< 5 %). Pairwise deletion vermeiden, da es zu unterschiedlichen Stichprobengrößen führt. Multiple Imputation oder FIML (Full Information Maximum Likelihood) sind moderne Alternativen bei mehr Missings.
Achtung: Standardverfahren wie MI und FIML setzen MAR voraus. Bei MNAR bleiben Verzerrungen möglich. Besprich das mit der Betreuung und führe Sensitivitätsanalysen durch.
Im Methodenteil solltest du dokumentieren: (1) Anteil pro Variable, (2) Muster (MCAR/MAR/MNAR), (3) gewählte Strategie (listwise, Imputation etc.), (4) Begründung und (5) finale Stichprobengröße nach Ausschlüssen.
„Die Rohdaten wurden vor der Analyse auf Plausibilität geprüft. [X] Fälle mit unvollständigen Angaben bei zentralen Variablen wurden ausgeschlossen (listwise deletion). Der Anteil fehlender Werte lag bei [X] %. Ausreißer wurden mittels Boxplots identifiziert; [X] Werte lagen außerhalb des 1,5-fachen Interquartilsabstands. Die finale Stichprobe umfasst n = [X]."
Software für die Datenanalyse
Die Wahl der Software hängt von deinen Vorkenntnissen, den Anforderungen deines Fachs und der Verfügbarkeit ab. Hier sind die gängigsten Tools mit ihren Stärken und Einsatzgebieten.

Stärken: Intuitive Menüführung, etabliert in Sozial- und Wirtschaftswissenschaften. Die meisten Standardverfahren sind per Klick zugänglich. Syntax speicherbar für Reproduzierbarkeit.
Grenzen: Kostenpflichtig, weniger flexibel bei komplexen oder neuen Verfahren.
Gut für: Einsteigende, Umfrageauswertungen, klassische statistische Tests.
Stärken: Kostenlos, extrem flexibel, riesige Community. Reproduzierbare Analysen durch Skripte. Hervorragende Visualisierungen (ggplot2).
Grenzen: Steilere Lernkurve, erfordert Programmierbereitschaft.
Gut für: Fortgeschrittene Analysen, reproduzierbare Forschung, anspruchsvolle Visualisierungen.
Stärken: Dateneingabe, einfache deskriptive Statistik (Mittelwerte, Häufigkeiten), Diagramme, Pivot-Tabellen.
Grenzen: Nicht geeignet für komplexe Inferenzstatistik (Regression etc.), fehleranfällig, schwer reproduzierbar. In Masterarbeiten meist nur als Vorstufe.
Tipp: Daten in Excel vorbereiten, dann in SPSS/R importieren.
Stärken: Kostenlos, vielseitig (auch Machine Learning, Textanalyse). Hervorragend bei sehr großen Datensätzen.
Grenzen: Programmierung erforderlich, Statistik-Workflows weniger spezialisiert als in R.
Gut für: Interdisziplinäre Projekte, Automatisierung, Machine Learning.
Voraussetzungen prüfen
Jedes statistische Verfahren hat Annahmen. Wenn diese verletzt sind, können Ergebnisse irreführend sein. Hier sind die wichtigsten Checks mit konkreten Handlungsoptionen.
Prüfen: Histogramm und Q-Q-Plot visuell beurteilen. Shapiro-Wilk-Test bei kleineren Stichproben. Schiefe und Kurtosis als Kennzahlen.
Zur „n > 30"-Faustregel: Parametrische Tests sind oft robust, aber Schwellenwerte sind keine Garantie. Schau dir die Daten immer visuell an. Bei starken Ausreißern können auch große Stichproben problematisch sein.
Wenn verletzt: Nicht-parametrische Alternative (Mann-Whitney, Spearman) oder robuste Varianten nutzen. Dokumentiere dies im Methodenteil.
Prüfen: Levene-Test. Ein signifikantes Ergebnis (p < .05) bedeutet ungleiche Varianzen.
Wenn verletzt: Welch-t-Test statt klassischem t-Test. Bei ANOVA: Welch-ANOVA oder Games-Howell Post-hoc.
Linearität: Streudiagramm Residuen vs. vorhergesagte Werte. Kein Muster → okay.
Homoskedastizität: Residuenplot prüfen. Trichterform → Heteroskedastizität. Alternative: robuste Standardfehler wie HC3.
Multikollinearität: VIF (Variance Inflation Factor) prüfen. VIF > 10 deutet auf Probleme hin. Lösung: Variablen zusammenfassen oder theoretisch begründet entfernen.
Einflussreiche Fälle: Cook's Distance > 1 oder > 4/n prüfen. Analyse mit und ohne diese Fälle vergleichen.
Statistische Verfahren auswählen
Das richtige Verfahren hängt von deiner Forschungsfrage, dem Skalenniveau und der Datenstruktur ab. Hier findest du eine Entscheidungshilfe für die gängigsten Situationen.
M = Mittelwert, SD = Standardabweichung, n = Stichprobengröße, df = Freiheitsgrade, p = p-Wert.
CI = Konfidenzintervall, SE = Standardfehler, AV/UV = Abhängige/Unabhängige Variable.
β/B = Regressionsgewichte, R² = erklärte Varianz, α = Cronbachs Alpha oder Signifikanzniveau.
Formate können je nach Fach (z. B. APA) leicht variieren. Folge im Zweifel den Vorgaben deiner Betreuung.
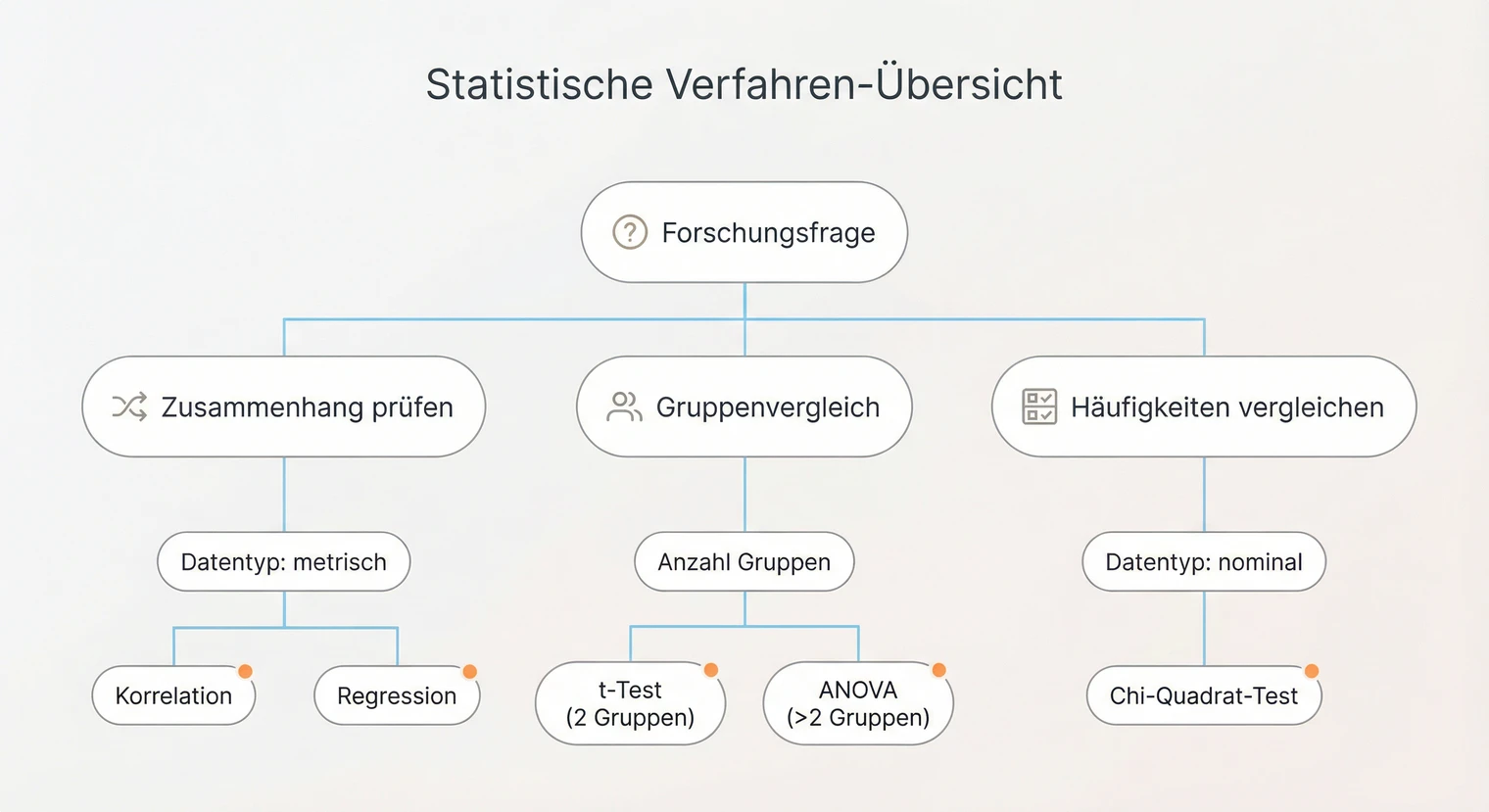
Zusammenhang zweier Variablen
Metrisch + Normalverteilung → Pearson. Ordinal oder Verletzung → Spearman. Berichten: r, p, 95 % CI.
Zwei unabhängige Gruppen vergleichen
Metrisch + Voraussetzungen → t-Test unabhängig. Verletzung → Mann-Whitney-U. Berichten: t(df), p, d.
Mehr als zwei Gruppen vergleichen
Metrisch + Voraussetzungen → ANOVA + Post-hoc. Verletzung → Kruskal-Wallis. Berichten: F(df1, df2), p, η²p.
Bei Messwiederholung: Mauchly-Test auf Sphärizität prüfen. Bei Verletzung: Greenhouse-Geisser oder Huynh-Feldt Korrektur.
Vorhersage / Einfluss (Regression)
AV metrisch: Lineare Regression. Berichten: B, SE, β, t, p pro Prädiktor; R², F für Gesamtmodell.
AV binär: Logistische Regression. Berichten: B, Wald, p, Odds Ratio (OR) mit CI, Pseudo-R².
Zusammenhang kategorialer Variablen
Beide nominal → Chi-Quadrat-Test. Bei Verletzung: Fisher's Exact Test.
Berichten: χ²(df), p, Cramér's V.
Bei der Auswahl des Verfahrens gilt: Die Forschungsmethode bestimmt den Rahmen, die Datenstruktur die konkrete Analyse. Wenn du unsicher bist, prüfe die Voraussetzungen und konsultiere Methodenliteratur oder deine Betreuung.
Skalen und Messmodelle
In vielen Masterarbeiten werden Konstrukte mit mehreren Items gemessen, etwa Arbeitszufriedenheit oder Stresserleben. Dabei gibt es typische Stolperstellen, die du kennen solltest.
Einzelitem vs. Skala: Ein einzelnes Likert-Item (1–5) ist streng genommen ordinal. Erst der Mittelwert mehrerer Items einer Skala wird oft als näherungsweise metrisch behandelt.
Skalenbildung: Berechne den Mittelwert oder die Summe der Items. Prüfe vorher, ob alle Items in dieselbe Richtung gepolt sind.
Invertierte Items: Gegensätzlich formulierte Items müssen vorab umkodiert werden. Formel: neuer Wert = (max + 1) – alter Wert.
Cronbachs Alpha: Misst die interne Konsistenz. α ≥ .70 gilt oft als akzeptabel. Bei sehr hohem Alpha (> .95) auf Redundanz prüfen.
Berichten: „Die interne Konsistenz der Skala [Name] war gut (α = .XX)." Verweise bei etablierten Skalen immer auf die Originalquelle.
Tipp: Prüfe „Alpha wenn Item gelöscht". Steigt der Wert deutlich, passt das Item evtl. nicht zur Skala.
Qualitative Datenanalyse
Bei qualitativen Daten wie Interviewtranskripten, Beobachtungsprotokollen oder Dokumenten folgt die Analyse anderen Prinzipien. Statt Zahlen stehen Bedeutungen und Muster im Fokus.
Vorgehen: Du entwickelst ein Kategoriensystem (deduktiv aus Theorie oder induktiv aus dem Material), ordnest Textstellen Kategorien zu (Codieren) und verdichtest diese zu Ergebnissen.
Codebuch: Definiere für jede Kategorie: Name, Definition, Ankerbeispiel und Abgrenzung. Das Codebuch gehört in den Anhang deiner Arbeit.
Kategorie: Arbeitszufriedenheit
Definition: Positive oder negative Bewertung der eigenen Arbeitssituation.
Ankerbeispiel: „Im Großen und Ganzen bin ich zufrieden mit meinem Job."
Nicht: Reine Tätigkeitsbeschreibungen ohne Bewertung.
Kategorie: Work-Life-Balance
Definition: Aussagen zur Vereinbarkeit von Beruf und Privatleben.
Ankerbeispiel: „Ich schaffe es kaum, Zeit für die Familie zu haben."
Nicht: Aussagen zu Arbeitszeiten ohne Bezug zum Privatleben.
Transparenz: Dokumentiere Sampling, Erhebung und Codierung so, dass sie für Dritte rekonstruierbar sind. Nutze Memos für Interpretationsideen.
Konsensuelle Codierung: Codiere einen Teil des Materials mit einer zweiten Person, um die Intersubjektivität zu erhöhen.
Revisionsrunde: Überprüfe dein Kategoriensystem nach dem ersten Durchlauf und schärfe Definitionen bei Bedarf nach.
Ergebnisse darstellen und berichten
Die Darstellung deiner Ergebnisse sollte klar, präzise und nachvollziehbar sein. Hier findest du konkrete Formulierungsbausteine, die du anpassen kannst.
t-Test
„Die Experimentalgruppe (M = X.XX, SD = X.XX) erzielte signifikant höhere Werte als die Kontrollgruppe (M = X.XX, SD = X.XX), t(df) = X.XX, p = .XXX, d = X.XX, 95 % CI [X.XX, X.XX]."
ANOVA
„Es zeigte sich ein signifikanter Haupteffekt des Faktors [Name], F(df1, df2) = X.XX, p = .XXX, η²p = .XX. Post-hoc-Vergleiche (Bonferroni) ergaben einen signifikanten Unterschied zwischen Gruppe A und B (p = .XXX)."
Bei Messwiederholung: „Sphärizität wurde verletzt (Mauchly-Test p < .05), daher wurden Greenhouse-Geisser-korrigierte Werte berichtet (ε = .XX). Der Haupteffekt Zeit war signifikant, F(df1korr, df2korr) = X.XX, p = .XXX."
Korrelation / Regression
„Zwischen [V1] und [V2] bestand ein signifikanter positiver Zusammenhang, r = .XX, p = .XXX."
„Das Modell war signifikant, F(df1, df2) = X.XX, p < .001, R² = .XX. [Prädiktor] war ein signifikanter Prädiktor (β = .XX, p = .XXX)."
Chi-Quadrat
„Der Chi-Quadrat-Test zeigte einen signifikanten Zusammenhang zwischen [V1] und [V2], χ²(df) = X.XX, p = .XXX, V = .XX."
Cohens d: 0.2 = klein, 0.5 = mittel, 0.8 = groß. r: .10 = klein, .30 = mittel, .50 = groß. η²: .01 = klein, .06 = mittel, .14 = groß.
Wichtig: Diese Werte sind Orientierungshilfen. Ordne Effekte immer im Kontext deiner Forschungsdisziplin ein.
„Als zentrale Kategorie wurde [Name] identifiziert. [X] von [Y] Befragten thematisierten diesen Aspekt."
„Exemplarisch zeigt sich dies in der Aussage von Person A: ‚[Zitat]' (Interview A, Z. 45–48)."
„Abweichend davon äußerte Person C eine gegenteilige Einschätzung: ‚[Zitat]' (Interview C, Z. 78)."
Tipp: Zitate mit [...] kürzen, ohne den Sinn zu verändern. Nutze Zeilenangaben für maximale Transparenz.
Typische Fehler und Analyse-Fallen
Bei der Datenanalyse passieren einige Fehler immer wieder. Hier sind die häufigsten mit konkreten Gegenmaßnahmen.
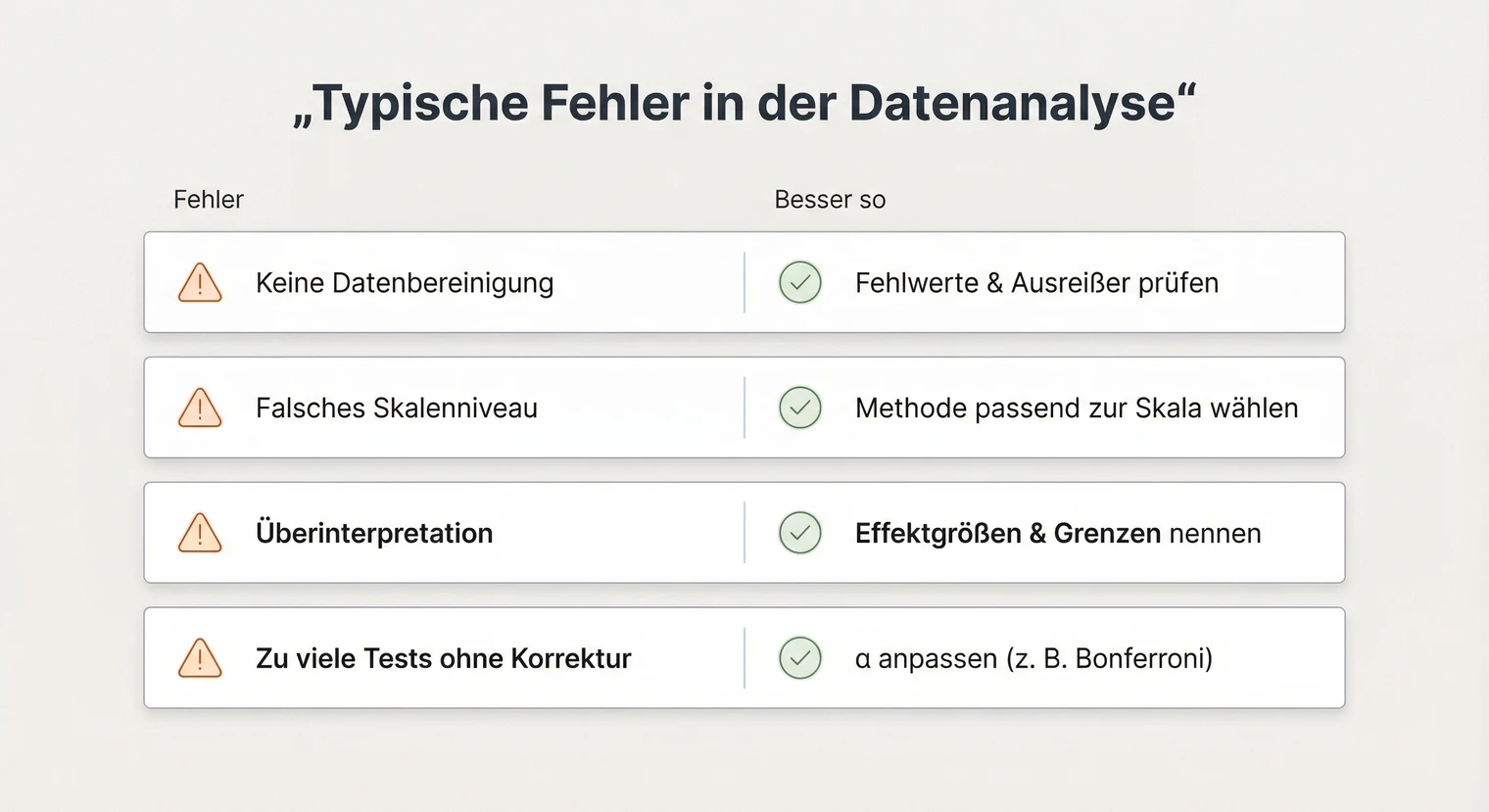
Datenaufbereitung vernachlässigen: Wer direkt mit der Analyse startet, übersieht oft Fehler in den Daten. Vermeidung: Nimm dir Zeit für die Datenprüfung. Kontrolliere Häufigkeiten, Minima und Maxima aller Variablen.
Voraussetzungen nicht prüfen: Jedes Verfahren hat Annahmen. Vermeidung: Siehe Abschnitt „Voraussetzungen prüfen" oben. Dokumentiere die Prüfung im Methodenteil.
Multiple Tests / p-Hacking: Viele Tests ohne Korrektur erhöhen das Risiko von Zufallsbefunden. Lösung: Hypothesen vorab festlegen und ggf. Bonferroni-Korrektur anwenden.
Kausalitätsfehlschluss: Korrelation zeigt Zusammenhang, nicht Ursache. Vermeidung: Formuliere vorsichtig („steht im Zusammenhang mit"), statt Ursache-Wirkung zu behaupten.
Overfitting: Zu viele Prädiktoren bei kleiner Stichprobe können zu instabilen Modellen führen. Lösung: Leite Modellkomplexität und Stichprobengröße aus Design, erwarteter Signalstärke, Ereignisverteilung und geeigneter Validierung ab; eine starre Zahl pro Prädiktor reicht dafür nicht.
Zu kleine Stichprobe: Geringe statistische Power führt dazu, dass echte Effekte nicht entdeckt werden. Berichte in diesem Fall unbedingt Effektstärken und Konfidenzintervalle.
Nächste Schritte
Wenn du deine Datenanalyse abgeschlossen hast, folgen die letzten Schritte auf dem Weg zur Abgabe.
Ergebnisse in die Arbeit integrieren: Schreibe den Ergebnisteil. Strukturiere nach Forschungsfragen oder Hypothesen. Verweise auf Tabellen und Abbildungen. Halte die Darstellung sachlich, die Interpretation kommt in der Diskussion.
Diskussion schreiben: Ordne deine Ergebnisse in den Forschungskontext ein. Was bedeuten sie für die Theorie? Welche praktischen Implikationen gibt es? Benenne Limitationen und Ansatzpunkte für zukünftige Forschung.
Reproduzierbarkeit: Syntax/Skripte gespeichert, Analyseschritte dokumentiert, Rohdaten gesichert.
Reporting vollständig: Teststatistik, df, p-Wert, Effektstärke und n bei jedem Test angegeben.
Tabellen & Grafiken: Einheitliche Formatierung, klare Beschriftung und korrekte Verweise im Text.
Voraussetzungen: Prüfung im Methodenteil dokumentiert, Umgang mit Verletzungen begründet.
Anhang: Fragebogen, Codebuch (bei qualitativer Analyse) und ggf. ergänzende Tabellen beigefügt.
Vor der Abgabe steht die Plagiatsprüfung. Auch bei der Datenanalyse gilt: Übernommene Methoden oder Analysestrategien aus anderen Arbeiten solltest du korrekt kennzeichnen und zitieren.
Wenn du deine Masterarbeit drucken und binden lassen möchtest, kannst du das bei BachelorHero online konfigurieren. So hast du am Ende ein professionell gebundenes Exemplar für die Abgabe.
Häufig gestellte Fragen
Wie strukturiere ich den Ergebnisteil meiner Masterarbeit?
Strukturiere nach Forschungsfragen oder Hypothesen. Pro Abschnitt: (1) Deskriptive Befunde (M, SD, n), (2) Inferenzstatistik (Teststatistik, df, p, Effektstärke, ggf. CI), (3) Kurze Einordnung ohne Interpretation. Verweise auf Tabellen/Abbildungen im Fließtext. Die eigentliche Interpretation gehört in die Diskussion.
Welche Kennwerte muss ich in Tabellen angeben?
Bei deskriptiven Tabellen: M, SD, n, ggf. Range oder Median. Bei Inferenz: Teststatistik (t, F, χ²), Freiheitsgrade (df), p-Wert, Effektstärke (d, η², r). Bei linearer Regression: B, SE, β, t, p, R². Bei logistischer Regression: B, SE, Wald-χ²/z, p, Odds Ratio (OR) mit CI, Pseudo-R². Gib immer die Stichprobengröße an und beschrifte Zeilen/Spalten eindeutig. Fußnoten für Signifikanzniveaus (*p < .05).
Was mache ich, wenn meine Daten nicht normalverteilt sind?
Prüfe erst visuell, wie stark die Verletzung ist (Histogramm, Q-Q-Plot). Die „n > 30"-Faustregel ist eine Vereinfachung: Robustheit hängt vom Verfahren und der Art der Verletzung ab. Bei leichter Schiefe sind parametrische Tests oft tolerant, bei starken Ausreißern weniger. Im Zweifel: nicht-parametrische Alternative (Mann-Whitney statt t-Test, Spearman statt Pearson) als Sensitivitätsanalyse ergänzen und beide Ergebnisse berichten.
Wie begründe ich meine Testwahl im Methodenteil?
Nenne drei Punkte: (1) Forschungsfrage/Hypothese (z. B. „Um den Unterschied zwischen den Gruppen zu prüfen..."), (2) Datenstruktur (Skalenniveau, Design), (3) Voraussetzungsprüfung (z. B. „Der Levene-Test zeigte Varianzhomogenität, daher wurde ein t-Test durchgeführt"). Verweis auf Methodenliteratur optional.
Wie viele Daten brauche ich für eine statistische Auswertung?
Die nötige Stichprobengröße hängt stark von mehreren Faktoren ab: erwartete Effektgröße (kleine Effekte brauchen mehr Fälle), Varianz in den Daten, Anzahl der Prädiktoren, Design (Cluster, Messwiederholung) und Dropout/Missings. Zahlen wie „30 pro Gruppe" oder „10 Fälle pro Prädiktor" sind sehr grobe, unsichere Daumenregeln, keine Mindestanforderungen. Eine Power-Analyse (z. B. G*Power) hilft bei der Planung. Besprich das frühzeitig mit deiner Betreuung.
Wann nutze ich parametrische und wann nicht-parametrische Tests?
Parametrische Tests (t-Test, ANOVA) setzen voraus: metrisches Skalenniveau, annähernde Normalverteilung, Varianzhomogenität. Prüfe diese Annahmen. Bei Verletzung: nicht-parametrische Alternative (Mann-Whitney, Kruskal-Wallis, Spearman). Dokumentiere die Prüfung und deine Entscheidung.
Wie gehe ich mit fehlenden Werten um?
Dokumentiere Anteil und Muster (MCAR = komplett zufällig, MAR = zufällig bedingt auf andere Variablen, MNAR = systematisch). Bei wenigen zufälligen Missings (< 5 %, MCAR): listwise deletion oft vertretbar. Bei MAR: multiple Imputation oder Maximum-Likelihood-Verfahren (FIML). Achtung bei MNAR: Standardverfahren (MI/FIML) setzen MAR voraus und können bei MNAR verzerrt bleiben. Besprich das mit der Betreuung, nutze Sensitivitätsanalysen und begründe, warum MAR plausibel ist. Pairwise deletion vermeiden (unterschiedliche n). Pflicht-Dokumentation: (1) Anteil, (2) Muster, (3) Strategie, (4) Begründung, (5) finale n.
Wie interpretiere ich einen p-Wert richtig?
Der p-Wert gibt die Wahrscheinlichkeit an, die beobachteten oder extremere Daten zu erhalten, wenn die Nullhypothese stimmt. p < .05 heißt nicht „wichtiger Effekt". Berichte immer auch Effektstärke und ggf. CI. Ein signifikantes Ergebnis bei großer Stichprobe kann praktisch unbedeutend sein.
 Internetquellen richtig zitieren
Internetquellen richtig zitieren  Roter Faden in der Masterarbeit
Roter Faden in der Masterarbeit  Wissenschaftliche Kommunikation
Wissenschaftliche Kommunikation